
Neural Network and Back Propagation Algorithm
Neural networks are typically organized in layers. Layers are made up of a number of interconnected nodes which contain an activation function $h_\theta(z)$. Patterns $\mathbf{x}$ are presented to the network via the input layer, which communicates to one or more hidden layers where the actual processing is done via a system of weighted connections $\mathbf{\Theta}$. The hidden layers then link to an output layer where the predict answer $\mathbf{y}^{pred}$ is output as shown in the graphic below.
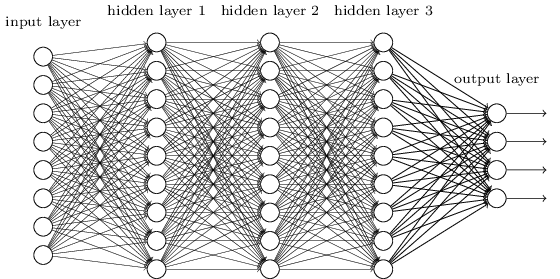
Math Model
Here, we use the sigmoid function as activation function:
which has a convenient derivative of:
We assume there are L layers of neural networks and label nodes of layer $i$ as $\mathbf{a}^{(i)}$ and call them “activation units”. The output of the $i^{th}$ layer is the input of the $i+1^{th}$ layer. In the input layer,
and in the output layer,
$\mathbf{a}^{(i)}$ can be solved in a feed-forward manner, as:
Given the trainning set $\{ (\mathbf{x}_1, \mathbf{y}_1), (\mathbf{x}_2, \mathbf{y}_2), \cdots, (\mathbf{x}_M, \mathbf{y}_M)\}$, the cost function for this neural network can be written as:
To ease the derivation, the above formulations can be written in indicial notation, as:
Following the Einstein summation convention, the repeated free indices are implicitly summed over their range.
The goal of the neural network trainning process is to find the weights $\Theta^{(i)}$ for $i\in\{1,2,\dots, L\}$ such that the cost function approach its maximum for all trianning set. In order to find the maximum by using the gradient descent method, we need to evaluate $J(\Theta)$ as well as the gradient $\frac{\partial{J}}{\partial{\theta^{(l)}_{ij}}}$.
Back propagation Algorithm
Back propagation is a method used in artificial neural networks to calculate the gradients of cost function. Indeed, back propagation is nothing but the chain rule for solving the derivative of compound functions. To demonstrate how it works, we start from the gradient of weights of the output layer ($l=L$):
where
with
where $\delta_{ij}$ is the Kronecker delta, with the property:
Hence,
The above formulation is indeed the gradient for logistic regression without regularization term. Now, let’s move one step ahead and find the derivatives of the cost function $J$ w.r.t. the weights $\theta^{(L-1)}_{ij}$. By the chain rule, we can use the formulation we derived above and write:
From $z_k^{(L)}=\theta_{km}^{(L)}a^{(L-1)}_m$, we have
In the Einstein summation convention, each index can appear at most twice in any term. And the index $m$ above does not indicate summation. Hence, we can define an auxiliary second order tensor
Then,
Following the same pattern, you can derive
By mathematical induction, you may find
For the regularized neural network, all you need to do is to add the derivative of the regularization term w.r.t. the corresponding weights, which is a trivial task.
Leave a Comment